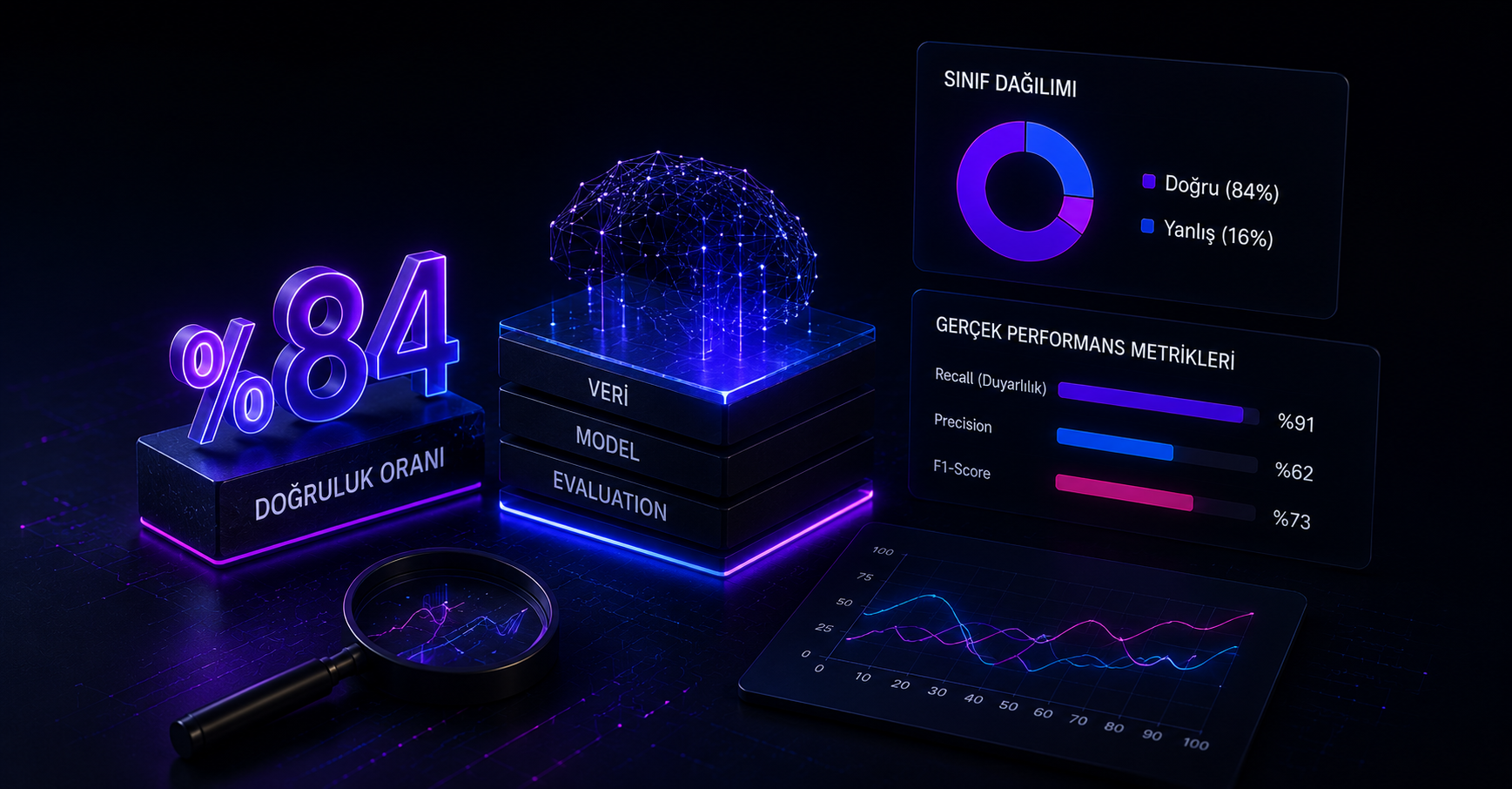
Modelin %84 Doğru Çıktıysa Hemen Sevinmemelisin
Spoiler
Bir model eğitirsin, en sona accuracy_score yazarsın, ekrana 0.84 düşer. İlk hissin sevinç olur değil mi — on tahminden sekiz buçuğu doğru, iyi iş. Ama açıkçası bu sayı seni een büyük tuzaklardan birinin tam ortasına çekebilir.
Ben bu tuzağa bir İK projesinde düştüm. Amaç basitti: bir şirketteki çalışanlar işten ayrılacak mı, ayrılmayacak mı, onu tahmin etmek (Attrition = Yes/No). Veri seti meşhur IBM HR formatına benziyordu — bir hedef sütun, geri kalan otuz küsür sütun feature. Modeli kurdum, accuracy %84, sevindim. Sonra confusion matrix'e baktım... ve olayı gördüm.
Bu yazıda sana class imbalance (sınıf dengesizliği) denen şeyi kendi düştüğüm çukur üzerinden anlatacağım: accuracy neden yalan söylüyor, onun yerine neye bakman lazım, ve dengeyi düzeltmek için elindeki yöntemlerden hangisini ne zaman kullanırsın.
Buradaki kodlar scikit-learn ve Python 3. Örnek olarak kendi HR Analytics projemi kullanıyorum — çalışanların ~%84'ü "kaldı", %16'sı "ayrıldı" olan, yani dengesiz bir veri.
%84 accuracy aslında niye hiçbir şey demek değil?
Bak şöyle: benim veride çalışanların %84'ü işte kalmış, sadece %16'sı ayrılmış. Yani sınıflar dengeli değil, bir taraf öbürünün tam beş katı.
Şimdi şöyle salak bir model hayal et: hiç düşünmeden herkese "ayrılmaz" diyen bir model. Tek satır mantık, sıfır öğrenme, hatta öğrenme bile değil. Bu modelin accuracy'si kaç olur sence?
# Model: ne sorarsan sor, cevap hep "ayrılmaz" (0)
# Veride zaten %84 ayrılmıyor
# → bu salak model bile %84 accuracy yaparİşte can alıcı yer burası. Benim saatlerce uğraşıp kurduğum "gerçek" modelin accuracy'si de %84 civarındaydı. Yani o emeğimin sonucu, hiçbir şey bilmeyen bir if-else kadar başarılı görünüyordu. Çünkü accuracy bütün tahminleri eşit sayıyor; sen ayrılanların (azınlığın) bir tekini bile bulamasan da, kalanları (çoğunluğu) doğru bilmen seni yüksek skora taşıyor.
Halbuki bu projenin bütün anlamı ayrılacak kişileri önceden yakalamak. Zaten kalacak olana "kalacak" demenin kimseye faydası yok; İK ekibi gidecek olanı önceden görmek istiyor. Yani modelin asıl iş yapması gereken yer, accuracy'nin en az umursadığı yer.
Kısaca: accuracy "kaç tahminim tuttu?" diye soruyor. Ama dengesiz veride asıl soru şu olmalı — "asıl önemli olan azınlığı yakalayabildim mi?" Bu ikisi aynı şey değil işte.
Peki neye bakacaksın? precision, recall, F1
Confusion matrix'e bakınca dört kutu çıkıyor karşına. Bunları ezberlemeye çalışma, İK örneğiyle düşün, çok daha kalıcı oluyor:
- TP: Ayrılacak dedim, gerçekten ayrıldı. ✓ Tam isabet.
- FP: Ayrılacak dedim, ama adam kaldı. → Boşa alarm.
- FN: Ayrılmaz dedim, ama ayrıldı. → Kaçırdım, en pahalı hata bu.
- TN: Ayrılmaz dedim, kaldı. ✓ Ama zaten kolay olanı.
Buradan iki tane çok önemli metrik çıkıyor:
Precision (kesinlik): "Ayrılacak" dediklerimin kaçı gerçekten ayrıldı? → TP / (TP + FP)
Yani çaldığım alarmların ne kadarı gerçekti? Düşükse, sürekli yanlış alarm veriyorsun demektir.
Recall (duyarlılık): Gerçekten ayrılanların kaçını yakalayabildim? → TP / (TP + FN)
Yani kaçırma oranım ne? Düşükse, riskli insanları gözden kaçırıyorsun.
Ve bunlar birbiriyle çekişiyor. Her şeye "ayrılacak" dersen recall tavan yapar (kimseyi kaçırmazsın) ama precision dibi görür (durmadan yanlış alarm). Tam tersi, aşırı temkinli olursan precision yükselir ama bu sefer recall düşer. F1 skoru da işte bu ikisini tek bir sayıda dengeleyen şey:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
# accuracy'ye değil, azınlık sınıfının (1) precision/recall/f1 satırına bakBenim için kafadaki ampul tam burada yandı: accuracy %84'tü ama ayrılanlar için recall utanılacak kadar düşüktü. Model dışarıdan "başarılı" görünüyordu, ama asıl işini hiç yapmıyordu.
Peki hangisine ağırlık vereceksin? Duruma bağlı:
Hızlıca özetlersem:
Kaçırmanın pahalı olduğu yerde (hastalık teşhisi, ayrılacak çalışan, saldırı tespiti) recall'a öncelik ver — çünkü bir taneyi bile kaçırmak çok şeye mal olur. Yanlış alarmın pahalı olduğu yerde (mesela spam filtresi önemli bir maili silmesin) precision önemli. İkisi de önemliyse ve tek bir sayı istiyorsan F1'e bak. Ve sınıfların dengesizse, accuracy'ye sakın güvenme — o sadece çoğunluğu ezberler.
Benim İK örneğinde öncelik recall'daydı. Çünkü ayrılma riski olan birini kaçırmak, birine boşuna "riskli" demekten çok daha pahalıya patlıyor.
Dengeyi nasıl düzeltirsin? class_weight, SMOTE, threshold
Doğru metriğe bakmak sorunu görmeni sağlar, ama çözmez. Dengesizlikle baş etmek için üç ana yol var. Ben projemde birini kullandım, birini hiç denemedim — ikisini de olduğu gibi anlatayım, çünkü dürüst olmak en önemlisi bana göre.
Yol 1 — class_weight="balanced" (benim kullandığım)
En basiti ve bence ilk denemen gereken şey bu. Modele diyorsun ki: "azınlığı yanlış bilmen, çoğunluğu yanlış bilmekten daha pahalı sayılsın." O da azınlığa daha fazla dikkat etmeye başlıyor. Tek bir parametre, o kadar:
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
lr = LogisticRegression(max_iter=1000, class_weight="balanced")
rf = RandomForestClassifier(n_estimators=200, class_weight="balanced", random_state=42)Veriye hiç dokunmuyor, sentetik bir şey üretmiyor, sadece kayıp fonksiyonundaki ağırlıkları oynatıyor. Hızlı, tertemiz, başlangıç için birebir. Ben hem Logistic Regression hem Random Forest'ta bunu kullandım. Accuracy biraz düştü ama azınlığın recall'u gözle görülür şekilde yükseldi — ki zaten istediğim de oydu.
Yol 2 — SMOTE (henüz denemedim ama merak ediyorum)
SMOTE şunu yapıyor: azınlık sınıfının sahte ama mantıklı yeni örneklerini üretiyor. Var olan azınlık noktalarının arasına "ara değerler" koyarak veriyi yapay olarak dengeliyor. Kopyalamıyor dikkat et, aralara yeni noktalar serpiştiriyor.
# imbalanced-learn kütüphanesi lazım
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_train_res, y_train_res = sm.fit_resample(X_train, y_train)Bunu projemde daha denemedim, README'ye "sonraki versiyonda dener miyim" diye not düşmüştüm. Ama bir şeyi sakın atlama: SMOTE sadece eğitim setine uygulanır, test setine asla. Test setini sahte veriyle bulaştırırsan, modelin gerçek performansını değil hayali bir performansı ölçmüş olursun. O yüzden bölmeden sonra yaparsın.
Yol 3 — threshold (eşik) ayarlama
Aslında çoğu model sana direkt 0/1 vermiyor, bir olasılık üretiyor. Varsayılan eşik 0.5: olasılık 0.5'in üstündeyse "ayrılacak" diyor. Ama bu çizgiyi sen kaydırabilirsin. Daha çok riskli insan yakalamak (yani recall'u artırmak) istiyorsan eşiği aşağı çekersin:
proba = model.predict_proba(X_test)[:, 1]
y_pred = (proba >= 0.35).astype(int) # 0.5 yerine 0.35: daha hassasModeli yeniden eğitmene gerek yok, sadece karar verirken kullandığın çizgiyi oynatıyorsun. Çok hızlı ve precision/recall dengesini ince ayar yapmak için süper.
Özetle hangisi ne zaman:
Yani kabaca: hızlı başlamak ve veriye dokunmamak istiyorsan class_weight="balanced". Azınlık o kadar az ki model öğrenecek örnek bulamıyorsa SMOTE (ama sadece train'e!). Model zaten iyi, sadece precision/recall dengesini ayarlamak istiyorsan threshold ayarı. Hiçbiri tek başına yetmiyorsa birkaçını birlikte dene.
Buradan çıkardığım en önemli ders şu: her dengesiz veri SMOTE istemiyor. Çoğu zaman class_weight + doğru metrik seçimi işi hallediyor. Benim projemde de öyle oldu zaten.
Bir de şu var: stratified split
Bütün bunlardan önce, çok kolay gözden kaçan ama kritik bir şey var. Veriyi train/test diye böldüğünde, dengesiz bir veride şansa bakar azınlığın büyük kısmı tek tarafa düşebilir. Bunu engellemek için bölmeyi sınıf oranını koruyarak yaparsın:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y # <- işte bu
)stratify=y sayesinde hem train'de hem test'te aynı %84/%16 oranı korunuyor. Bunu yazmazsan, zaten az olan azınlık test setinde iyice azalabilir ve metriklerin gürültüye boğulur. Minik bir parametre ama kocaman bir fark.
Toparlayalım
Dengesiz veride accuracy seni kandırır: sadece çoğunluğu ezberleyen salak bir model bile yüksek accuracy alır. Senin bakman gereken şey azınlık sınıfının precision, recall ve F1 değerleri; kaçırmanın pahalı olduğu yerde (ayrılacak çalışan, hastalık, saldırı) recall'a öncelik ver. Dengeyi düzeltmek için önce en basiti olan class_weight="balanced"'ı dene; yetmezse SMOTE ile azınlığı çoğalt (ama sadece eğitim setinde); precision/recall dengesini ince ayar yapmak için threshold'u kaydır. Ve hepsinden önce, bölmeyi stratify=y ile yap, sakın unutma.
Ben bu projede class_weight="balanced" + stratified split + F1/recall odaklı bakış kullandım. SMOTE hâlâ deneme listemde — çünkü bazı problemlerde gerçekten fark yaratıyor, bazılarında ise boşa karmaşıklık. Hangisinin senin verinde işe yaradığını söyleyecek tek şey, denemek ve doğru metriğe bakmak. O kadar.
İlgili proje: github.com/nisakayaa/hr-analytics — Logistic Regression ve Random Forest ile çalışan ayrılma tahmini.

